Implementing joins algorithms – Arrays, collections and data structures
123. Implementing joins algorithms
Joins algorithms are typically used in databases. Mainly, we have two tables in a one-to-many relationship and we want to fetch a result set containing this mapping based on a join predicate. In the following figure, we have the author and book tables. An author has multiple books and we want to join these tables to obtain a result set as the third table.
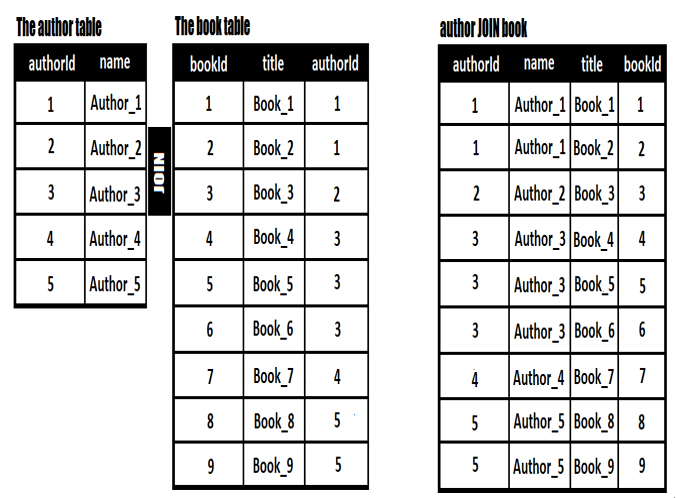
Figure 5.46 – Joining two tables (author and book)
There are three popular join algorithms for solving this problem: Nested Loop Join, Hash Join, and Sort Merge Join. While databases are optimized to choose the proper one depending on the query, let’s try to implement them in plain Java on the following two tables expressed as records:
public record Author(int authorId, String name) {}
public record Book(int bookId, String title, int authorId) {}
List<Author> authorsTable = Arrays.asList(
new Author(1, “Author_1”), new Author(2, “Author_2”),
new Author(3, “Author_3”), new Author(4, “Author_4”),
new Author(5, “Author_5”));
List<Book> booksTable = Arrays.asList(
new Book(1, “Book_1”, 1), new Book(2, “Book_2”, 1),
new Book(3, “Book_3”, 2), new Book(4, “Book_4”, 3),
new Book(5, “Book_5”, 3), new Book(6, “Book_6”, 3),
new Book(7, “Book_7”, 4), new Book(8, “Book_8”, 5),
new Book(9, “Book_9”, 5));
Our goal is to join the Author and Book records by matching the Author.authorId and Book.authorId attributes. The result should be a projection (ResultRow) that contains authorId, name, title, and bookId:
public record ResultRow(int authorId, String name,
String title, int bookId) {}
Next, let’s talk about Nested Loop Join.
Nested Loop Join
The Nested Loop Join algorithm relies on two loops that traverse both relations to find records that are matching the joining predicate:
public static List<ResultRow> nestedLoopJoin(
List<Author> authorsTable, List<Book> booksTable) {
List<ResultRow> resultSet = new LinkedList();
for (Author author : authorsTable) {
for (Book book : booksTable) {
if (book.authorId() == author.authorId()) {
resultSet.add(new ResultRow(
author.authorId(), author.name(),
book.title(), book.bookId()));
}
}
}
return resultSet;
}
The time complexity of this algorithm is O(n*m) where n is the size of authorsTable and m is the size of booksTable. So, having a quadratic complexity makes this algorithm useful only for small data sets.
Hash Join
As the name suggests, Hash Join relies on hashing. So, we have to create a hash table from authors (the table with fewer records) and afterward we loop the books to find their authors in the created hash table as follows:
public static List<ResultRow> hashJoin(
List<Author> authorsTable, List<Book> booksTable) {
Map<Integer, Author> authorMap = new HashMap<>();
for (Author author : authorsTable) {
authorMap.put(author.authorId(), author);
}
List<ResultRow> resultSet = new LinkedList();
for (Book book : booksTable) {
Integer authorId = book.authorId();
Author author = authorMap.get(authorId);
if (author != null) {
resultSet.add(new ResultRow(author.authorId(),
author.name(), book.title(), book.bookId()));
}
}
return resultSet;
}
The time complexity of this algorithm is O(n+m) where n is the size of authorsTable and m is the size of booksTable. So, this is better than Nested Loop Join.
Sort Merge Join
As the name suggests, Sort Merge Join starts by sorting the two tables by the attribute of the join. Afterward, we loop the two tables and apply the join predicate as follows:
public static List<ResultRow> sortMergeJoin(
List<Author> authorsTable, List<Book> booksTable) {
authorsTable.sort(Comparator.comparing(Author::authorId));
booksTable.sort((b1, b2) -> {
int sortResult = Comparator
.comparing(Book::authorId)
.compare(b1, b2);
return sortResult != 0 ? sortResult : Comparator
.comparing(Book::bookId)
.compare(b1, b2);
});
List<ResultRow> resultSet = new LinkedList();
int authorCount = authorsTable.size();
int bookCount = booksTable.size();
int p = 0;
int q = 0;
while (p < authorCount && q < bookCount) {
Author author = authorsTable.get(p);
Book book = booksTable.get(q);
if (author.authorId() == book.authorId()) {
resultSet.add(new ResultRow(author.authorId(),
author.name(), book.title(), book.bookId()));
q++;
} else {
p++;
}
}
return resultSet;
}
The time complexity of the Sort Merge Join algorithm O(n log(n) + m log(m))) where n is the size of authorsTable and m is the size of booksTable. So, this is better than Nested Loop Join and Hash Join.
Summary
In this chapter, we have covered a lot of interesting topics. We started with the new Vector API for empowering parallel data processing, we continued with a bunch of cool data structures like Zipper, K-D Trees, Skip List, Binomial Heap, and so on, and we’ve ended up with a nice coverage of the three main join algorithms.